In 2025, the landscape of artificial intelligence has evolved rapidly, and one clear trend has emerged: static AI models are no longer enough. As users demand more accurate, personalized, and up-to-date information, a new paradigm has taken center stage—Retrieval-Augmented Generation (RAG).
RAG systems combine the generative power of large language models (LLMs) with the precision of a search engine. Instead of relying solely on what a model “knows” from training data, RAG dynamically pulls relevant information from external sources—like PDFs, websites, or databases—at the time of the request. The result? Smarter, more grounded, and more trustworthy AI responses.
From enterprise knowledge assistants to legal research bots and educational tutors, RAG is now at the heart of many cutting-edge applications. It solves a fundamental limitation of LLMs: hallucination. By grounding generation in real data, RAG systems increase factual accuracy and transparency—something critical in business, healthcare, law, and education.
But with more tools and model options than ever before, how do you actually build one?
This guide walks you through each step of building a modern RAG system in 2025—from preparing your data and choosing the right embeddings, to deploying your assistant and adding feedback loops. Whether you’re a developer, startup founder, or AI enthusiast, this step-by-step breakdown will give you the clarity and confidence to build your own custom RAG solution—one that truly understands your data and delivers value in real time.
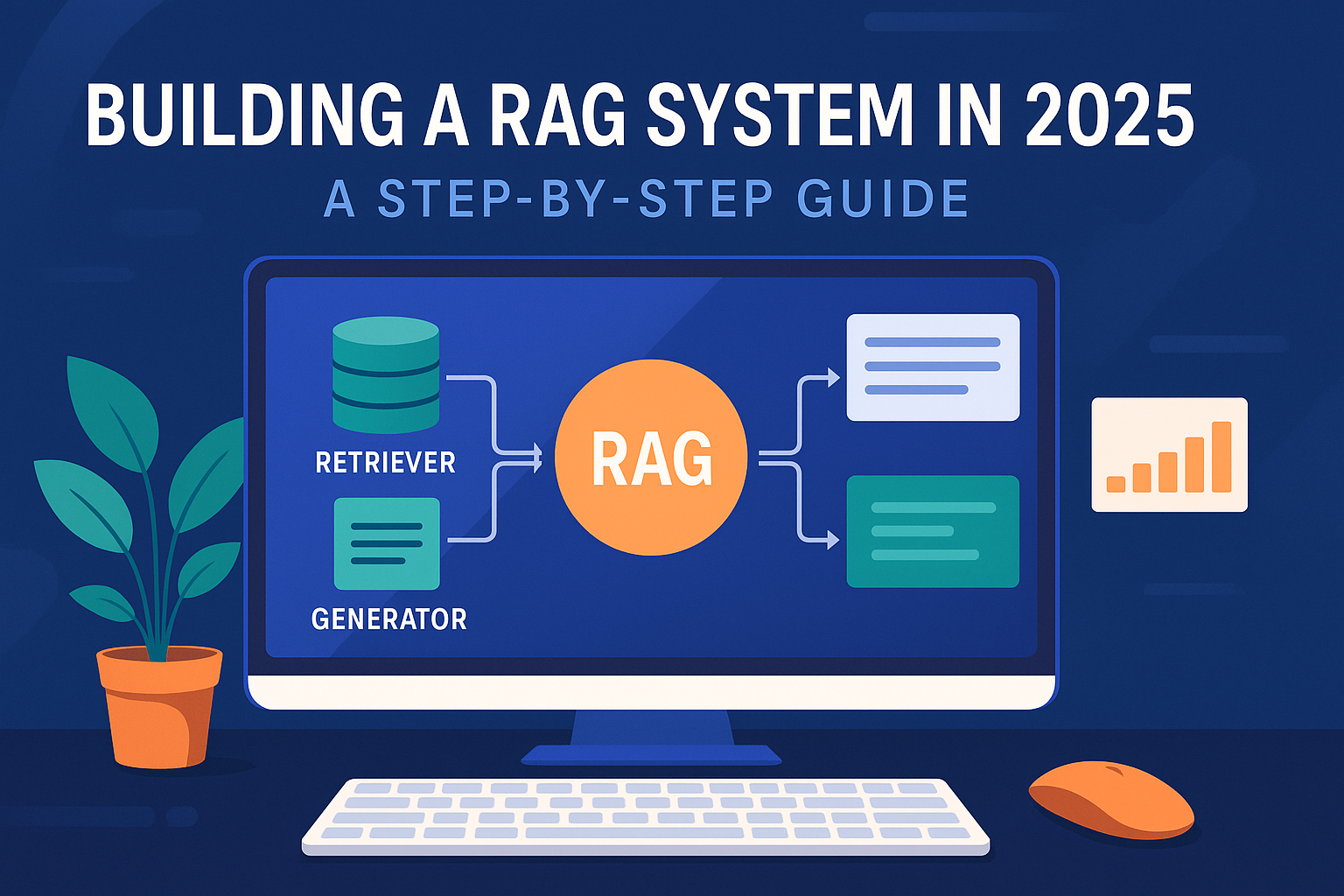
Step 1: Understand the RAG Architecture
To build a solid Retrieval-Augmented Generation (RAG) system, you first need to grasp how its architecture works and why it matters. At a glance, RAG may seem like just another AI buzzword, but it represents a major shift in how language models interact with information. Traditional LLMs generate responses based only on what they’ve been trained on, meaning they can become outdated or hallucinate facts. RAG systems solve this by injecting real, contextual data into the generation process—bridging the gap between static knowledge and dynamic information access.
At the heart of a RAG system are two tightly linked components: retrieval and generation. When a user enters a query, it isn’t sent directly to the language model. Instead, it first goes through a retrieval mechanism designed to search through a curated knowledge base—usually stored as vector embeddings in a specialized database. The retriever identifies and selects the most relevant documents or chunks of text that match the meaning of the query, not just the keywords. These retrieved chunks, often taken from your own data sources like PDFs, websites, or internal wikis, are then passed along with the original query to the language model.
The generator takes this retrieved context and uses it to craft a response that is more accurate, specific, and grounded in real data. This architecture is what sets RAG systems apart from basic chatbot setups. Rather than relying on what the model “remembers” from its training, it dynamically accesses external information in real time. The model becomes a reasoning engine rather than a knowledge store.
By understanding this fundamental architecture, you begin to see why RAG systems are so powerful in 2025. They are no longer just research experiments—they’re practical, scalable, and increasingly essential in domains like healthcare, law, education, and enterprise support. And everything you build from this point on will revolve around how well you design this retrieval-generation pipeline.
Step 2: Prepare Your Data
Once you understand the RAG architecture, the next critical step is preparing your data. This is where most of the groundwork happens—and where the success of your system is often determined. A RAG model is only as good as the information it can retrieve, so the way you structure, clean, and segment your content plays a direct role in how accurate and useful your answers will be.
Start by gathering the right content. This could be anything relevant to your use case: PDFs, research papers, customer support docs, internal knowledge bases, scraped web pages, legal documents, technical manuals, or even transcribed meetings. It doesn’t have to be perfect at first, but it should be comprehensive and relevant to the domain your RAG system is serving.
Once you’ve collected your source materials, the next step is breaking them down into manageable pieces. Language models struggle with large blocks of text, so instead of storing entire documents, you’ll need to split them into chunks—typically a few hundred words each. The goal is to make each chunk meaningful and self-contained, so when it’s retrieved later, it provides value on its own. Most systems use sliding window or recursive text splitting techniques with some overlap to preserve context across chunk boundaries.
In addition to chunking the data, enriching it with metadata can dramatically improve retrieval. Attach attributes like document titles, publication dates, tags, or categories to each chunk. This extra layer of context allows you to apply filters during search—helping the system prioritize content from certain sources, timeframes, or topics.
At this stage, you’re laying the foundation for the retriever. Poorly structured or irrelevant data can lead to noisy results and weak responses, no matter how advanced your language model is. But well-prepared, semantically rich chunks with clean formatting and thoughtful metadata give your system the precision and depth it needs to deliver real value.
Preparing data isn’t glamorous—but it’s essential. Treat it as a core investment, not a quick preprocessing step. The better your data foundation, the smarter and more trustworthy your RAG system will be.
Step 3: Embed the Data into a Vector Store
With your content cleaned, chunked, and enriched, the next step is turning that raw text into something your RAG system can efficiently search—embeddings. This is where the magic of semantic search begins. Instead of matching keywords, your system will now understand the meaning behind a user’s query and retrieve the most contextually relevant information from your data.
Embedding is the process of converting each text chunk into a high-dimensional vector—a numeric representation that captures the semantics of the text. In simple terms, you’re teaching your system to recognize the underlying intent and concept behind each paragraph, not just its surface-level words. This step transforms your entire knowledge base into a format that can be searched intelligently.
To do this, you’ll use a pre-trained embedding model. In 2025, you have a wide range of high-quality options, from OpenAI’s latest embedding models to Cohere, HuggingFace transformers, or open-source alternatives like BGE and E5. Choosing the right model depends on your language, performance needs, and budget. Accuracy matters here—a strong embedding model ensures your retriever pulls up the most meaningful matches.
Once embeddings are generated, they need to be stored somewhere accessible and searchable. This is where a vector store comes in. It acts like a search engine for your embeddings. Popular choices today include Pinecone, Weaviate, Qdrant, and Chroma, each offering various features like metadata filtering, hybrid search (vector + keyword), and scalability. You simply upload each vector along with its associated chunk of text and metadata, and the store handles the rest.
This process—embedding your knowledge and storing it in a vector database—is the technical backbone of retrieval in a RAG system. Without it, your model would be guessing in the dark. With it, you’ve now equipped your system to understand your documents and locate relevant context in milliseconds. It’s the bridge between raw content and intelligent answers.
Embedding may sound like a technical detail, but in truth, it’s one of the most important steps in building a reliable RAG pipeline. The more accurate and semantically rich your vectors, the more useful your retrieval—and, by extension, your generated responses—will be.
Step 4: Build the Retriever
With your data embedded and stored in a vector database, it’s time to build the component that actively connects user queries to the most relevant content: the retriever. This is the engine that powers the first half of the RAG system, responsible for finding the right chunks of information from your knowledge base and passing them to the language model.
At its core, the retriever takes a user’s question, converts it into an embedding using the same model you used for your documents, and then performs a similarity search against the stored vectors. Rather than relying on exact keyword matches like traditional search engines, it finds content that is semantically close—meaning it understands relevance at a conceptual level, not just a linguistic one.
But retrieval today goes beyond just grabbing the “top 3 similar results.” In 2025, more advanced strategies are commonly used to boost the quality and precision of what’s retrieved. For instance, you can apply metadata filters to limit results based on tags, categories, document types, or dates—retrieving only content that’s contextually appropriate. This is especially useful in enterprise applications where certain types of documents may take precedence over others.
Another effective refinement is multi-query expansion, where the system rephrases the user’s query into multiple alternate forms and uses those to gather a wider set of candidate documents. This helps capture nuanced meaning that a single query embedding might miss. The retriever can also incorporate reranking, where initial results are sorted again using more advanced models to prioritize not just similarity, but usefulness.
At this point, your retriever becomes more than just a basic search tool—it’s a smart filter that understands the question, considers the context, and delivers only the most relevant data to the generator. This is critical, because the quality of the retrieved documents directly influences the quality of the final answer. A great generator won’t help if it’s working with weak or irrelevant context.
So, when building your retriever, think of it as your system’s information gatekeeper. Fine-tune it, test it rigorously, and give it access to all the filtering tools your vector store and metadata provide. A strong retriever turns your static documents into a dynamic, searchable brain—ready to support the generation of grounded, trustworthy answers.
Step 5: Build the Generator
Here’s a simplified version of a Retrieval-Augmented Generation (RAG) system built using LangChain, OpenAI, and FAISS, without breaking it into points.
First, install the required Python packages:
pip install langchain openai faiss-cpu python-dotenv
Next, create a .env file and store your OpenAI API key like this:
OPENAI_API_KEY=your-api-key-here
Now here’s the full working code. This script loads a text file, splits it into chunks, creates vector embeddings, stores them in FAISS, retrieves relevant chunks based on a query, and uses an OpenAI model to generate an answer grounded in the retrieved content.
import os
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
Load the OpenAI API key
load_dotenv()
openai_api_key = os.getenv(“OPENAI_API_KEY”)
Load and prepare the data
loader = TextLoader(“data/sample.txt”) # Make sure you have this file
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = splitter.split_documents(documents)
Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
Set up retriever and language model
retriever = vectorstore.as_retriever(search_kwargs={“k”: 3})
llm = ChatOpenAI(model_name=”gpt-4″, temperature=0)
Build the RAG pipeline
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
Ask a question
query = “What is the main idea of the document?”
response = qa_chain({“query”: query})
Print the generated answer
print(“Answer:”)
print(response[“result”])
Optional: print source documents
print(“\nSources:”)
for doc in response[“source_documents”]:
print(doc.metadata)
This basic RAG setup reads from a .txt file and uses GPT-4 to answer questions based on that content. You can replace the file loader with one for PDFs or websites if needed. Let me know if you want it converted into a web app or integrated with voice or file upload features.
Step 6: Implement a Feedback Loop (Optional but Crucial)
Once your RAG system is able to retrieve documents and generate responses, the next step—while technically optional—is what separates a good system from a great one: feedback. In 2025, AI systems are expected to learn, adapt, and improve over time. A feedback loop is what makes that possible.
The idea is simple. Every time a user interacts with your system, they leave behind valuable signals—whether they liked the answer, whether they asked a follow-up, or whether they corrected the model. Capturing and analyzing this feedback helps you continuously refine everything from your prompt templates and retrieval logic to your data quality and chunking strategy.
You can start with a basic thumbs-up or thumbs-down option. Each time a user submits feedback, store it along with the original query, retrieved documents, and generated response. This creates a dataset you can review later to understand where your system is strong and where it falls short. Over time, this allows you to tune your retriever (e.g., adjust the number of chunks retrieved, improve metadata filtering) or even rethink how documents are chunked and embedded.
For example, if you notice the same type of question keeps returning incomplete answers, it might be a sign that relevant documents are missing or poorly structured. If users consistently ask follow-up questions to clarify something the system should have answered, it might mean your prompt needs to be more focused or your model should be instructed to be more specific.
You can also use feedback data to fine-tune rerankers, train custom embedding models, or improve your knowledge base. In more advanced setups, feedback can trigger automated workflows—like re-chunking documents that are underperforming or flagging responses for manual review.
A feedback loop doesn’t just improve accuracy—it builds trust. It shows users that your system is evolving, listening, and working to get better. And in the long run, it turns your static content into a living system that continuously learns and adapts with real-world use. Whether you’re building for five users or five million, investing in feedback early will pay off in reliability, engagement, and performance.
Step 7: Add Guardrails and Output Validation
After your RAG system is generating answers, it’s time to focus on making those answers safe, accurate, and trustworthy. Language models, even when grounded in retrieved documents, can still hallucinate or give overly confident responses. That’s why adding guardrails and output validation is essential—especially in domains like healthcare, law, education, or enterprise settings where accuracy truly matters.
Guardrails help set the boundaries for what your system should and shouldn’t say. This can include checking if the retrieved documents actually support the final answer, filtering out sensitive topics, or enforcing tone and formatting rules. For example, if your model is generating an answer about legal policy, but none of the retrieved documents include relevant laws, that should raise a flag.
One common way to validate output is by comparing the semantic similarity between the generated answer and the documents it was based on. If the answer goes far beyond what’s in the context—or introduces new claims that aren’t supported by the retrieved sources—it may be hallucinating. You can set a threshold and either warn the user, rephrase the answer, or even trigger a fallback message that encourages manual review.
Another good practice is adding source citations. Show users which document or page the answer was derived from. This adds transparency and makes it easier for users to verify the information. In some systems, you can even highlight which chunk of text the model used to form the answer.
Structured output formats, like JSON or bullet points, can also be enforced through prompts or response schema validators to ensure the model doesn’t stray off course—especially when integrating the output into another tool or interface. In more advanced systems, tools like LangChain’s guardrails, Rebuff, or OpenAI function calling can be used to control model behavior or correct it mid-process.
The goal here isn’t to restrict the model unnecessarily but to make sure its creativity is bounded by relevance, truth, and purpose. Guardrails build confidence—for both the developers and the end users—that the answers being generated are not only helpful but also responsible. In a world where AI is becoming a trusted decision-making assistant, those safety checks are no longer optional.
Step 8: Deploy and Integrate
With your RAG system built, refined, and validated, the final step is to bring it into the real world through deployment and integration. This is where your project moves from a working prototype to a usable product—whether it’s a web app, chatbot, internal tool, or API powering other systems.
Start by deciding how users will interact with your RAG system. If it’s a chat-based assistant, you might build a frontend using frameworks like Streamlit, React, or Flutter. For API-based use cases, FastAPI or Flask can expose your RAG pipeline as a service that other applications can consume. You’ll need to design simple endpoints where a user sends a query, and the server responds with the generated answer, optionally including sources or additional metadata.
When deploying to production, infrastructure becomes important. You’ll need to host your backend, store your documents securely, and manage your vector database. You can use cloud platforms like AWS, Google Cloud, Azure, or serverless options like Vercel or Render. If privacy is a concern, you might deploy the system entirely on-premises using tools like FAISS or Chroma and host an open-source language model locally.
Security also plays a key role at this stage. Set up authentication if your app deals with personal or proprietary information. Rate-limit API access to prevent abuse. And if you’re collecting feedback or usage logs for improvement, ensure that you follow privacy regulations like GDPR or HIPAA where applicable.
For smooth user experiences, make sure your app handles latency well. Preload embeddings, optimize queries, and cache frequent answers if possible. You might also want to introduce UI elements like loading spinners, fallback messages when no good context is found, and a feedback form for users to rate responses.
Finally, think about how this RAG system fits into a larger ecosystem. It could be integrated into Slack, Microsoft Teams, or your internal dashboard. Or, it could act as a knowledge layer over your business documentation, product manuals, or CRM. Once integrated, the RAG assistant becomes not just a tech demo, but a daily-use, intelligent interface to your organization’s knowledge.
Deployment isn’t just about putting code online—it’s about creating a complete, accessible, and dependable user experience that makes the value of your AI assistant real and practical.
Conclusion
Building a RAG system in 2025 is no longer just a research experiment—it’s a practical and powerful way to bring real intelligence into any application. By combining retrieval with generation, you’re not just generating text; you’re creating answers rooted in facts, personalized to context, and grounded in real data. That shift—from prediction to precision—is what makes RAG so impactful in everything from customer support to legal research, educational tools, enterprise assistants, and beyond.
This journey begins with understanding the architecture: knowing how retrieval and generation work together. Then it moves through careful data preparation, embedding, and storage—steps that form the memory of your assistant. With retrieval set up to pull in the right context and a strong LLM guiding the output, your system becomes more than a chatbot—it becomes a reliable source of knowledge. And with guardrails, feedback loops, and thoughtful deployment, it evolves into something users can trust and depend on.
What sets successful RAG systems apart is not complexity—it’s clarity. A clear goal. Clean data. A well-structured prompt. And continuous improvement through feedback and iteration. Whether you’re building for a niche audience or a global user base, the same principles apply.
As AI becomes more deeply integrated into daily life and work, RAG systems will play a key role in making those interactions accurate, accountable, and useful. You now have the tools and understanding to create one—step by step, feature by feature, and eventually, system by system.
Your data has something to say. Now, you’ve built a system that can say it—intelligently, responsibly, and in real time.